10 R Skills Review
In this lesson you will take all of the skills you have learned up to this point and use them on a completely new set of data.
10.1 Tidying datasets
We are interested in looking at how the Cache la Poudre River’s flow changes over time and space as it travels out of the mountainous Poudre Canyon and through Fort Collins.
There are four stream flow monitoring sites on the Poudre that we are interested in: two managed by the US Geological Survey (USGS), and two managed by the Colorado Division of Water Resources (CDWR):
We are going to work through retrieving the raw data from both the USGS and CDWR databases.
10.1.1 Get USGS stream flow data
Using the dataRetrieval package we can pull all sorts of USGS water data. You can read more about the package, functions available, metadata etc. here: https://doi-usgs.github.io/dataRetrieval/index.html
# pulls USGS daily ('dv') stream flow data for those two sites:
usgs <- dataRetrieval::readNWISdv(siteNumbers = c("06752260", "06752280"), # USGS site code for the Poudre River at the Lincoln Bridge and the ELC
parameterCd = "00060", # USGS code for stream flow
startDate = "2020-10-01", # YYYY-MM-DD formatting
endDate = "2023-10-01") %>% # YYYY-MM-DD formatting
rename(q_cfs = X_00060_00003) %>% # USGS code for stream flow units in cubic feet per second (CFS)
mutate(Date = lubridate::ymd(Date), # convert the Date column to "Date" formatting using the `lubridate` package
Site = case_when(site_no == "06752260" ~ "Lincoln",
site_no == "06752280" ~ "Boxelder"))
# if you want to save the data:
#write_csv(usgs, 'data/review-usgs.csv')10.1.2 Get CDWR stream flow data
Alas, CDWR doesn’t have an R packge to easily pull data from their API like USGS does, but they do have user-friendly instructions about how to develop API calls.
Don’t stress if you have no clue what an API is! We will learn a lot more about them in 523A, but this is good practice for our function writing and mapping skills.
Using the “URL Generator” steps outlined, if we wanted data from 2020-2022 for the Canyon mouth side (site abbreviation = CLAFTCCO), it generates this URL to retrieve that data:
However, we want to pull this data for two different sites, and may want to change the year range of data. Therefore, we can write a function to pull data for our various sites and time frames:
# Functin to retrieve data
co_water_data <- function(site, start_year, end_year){
raw_data <- httr::GET(url = paste0("https://dwr.state.co.us/Rest/GET/api/v2/surfacewater/surfacewatertsday/?format=json&dateFormat=dateOnly&fields=abbrev%2CmeasDate%2Cvalue%2CmeasUnit&encoding=deflate&abbrev=",site,
"&min-measDate=10%2F01%2F", start_year,
"&max-measDate=09%2F30%2F", end_year))
# extract the text data, returns a JSON object
extracted_data <- httr::content(raw_data, as = "text", encoding = "UTF-8")
# parse text from JSON to data frame
final_data <- jsonlite::fromJSON(extracted_data)[["ResultList"]]
return(final_data)
}Now, lets use that function to pull data for our two CDWR sites of interest, which we can iterate over with map(). Since this function returns data frames with the same structure an variable names, we can use map_dfr() to bind the two data frames into a single one:
10.1.3 OR, read in the .csv’s we already generated and saved for you:
Read in our two data sets. You will find that they provide the same information (daily streamflow from 2020-2022) but their variable names and structures are different:
## Rows: 2191 Columns: 6
## ── Column specification ───────────────────────────────────────────────────────────────────────────────────────────────────
## Delimiter: ","
## chr (4): agency_cd, site_no, X_00060_00003_cd, Site
## dbl (1): q_cfs
## date (1): Date
##
## ℹ Use `spec()` to retrieve the full column specification for this data.
## ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.## Rows: 2147 Columns: 4
## ── Column specification ───────────────────────────────────────────────────────────────────────────────────────────────────
## Delimiter: ","
## chr (2): abbrev, measUnit
## dbl (1): value
## date (1): measDate
##
## ℹ Use `spec()` to retrieve the full column specification for this data.
## ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.When we look at these two datasets, we see they provide the same information (daily streamflow from 2020-2023) but their variable names and structures are different:
## Rows: 2,191
## Columns: 6
## $ agency_cd <chr> "USGS", "USGS", "USGS", "USGS", "USGS", "USGS", "USGS", "USGS", "USGS", "USGS", "USGS", "USGS", …
## $ site_no <chr> "06752260", "06752260", "06752260", "06752260", "06752260", "06752260", "06752260", "06752260", …
## $ Date <date> 2020-10-01, 2020-10-02, 2020-10-03, 2020-10-04, 2020-10-05, 2020-10-06, 2020-10-07, 2020-10-08,…
## $ q_cfs <dbl> 6.64, 7.41, 7.04, 6.84, 6.79, 7.81, 6.49, 11.30, 20.20, 15.20, 11.20, 11.80, 18.40, 19.90, 18.20…
## $ X_00060_00003_cd <chr> "A", "A", "A", "A", "A", "A", "A", "A", "A", "A", "A", "A", "A", "A", "A", "A", "A", "A", "A", "…
## $ Site <chr> "Lincoln", "Lincoln", "Lincoln", "Lincoln", "Lincoln", "Lincoln", "Lincoln", "Lincoln", "Lincoln…## Rows: 2,147
## Columns: 4
## $ abbrev <chr> "CLAFTCCO", "CLAFTCCO", "CLAFTCCO", "CLAFTCCO", "CLAFTCCO", "CLAFTCCO", "CLAFTCCO", "CLAFTCCO", "CLAFTCC…
## $ measDate <date> 2020-10-01, 2020-10-02, 2020-10-03, 2020-10-04, 2020-10-05, 2020-10-06, 2020-10-07, 2020-10-08, 2020-10…
## $ value <dbl> 42, 36, 34, 32, 35, 30, 30, 34, 34, 27, 21, 29, 26, 43, 39, 44, 39, 45, 46, 39, 36, 46, 65, 72, 60, 65, …
## $ measUnit <chr> "cfs", "cfs", "cfs", "cfs", "cfs", "cfs", "cfs", "cfs", "cfs", "cfs", "cfs", "cfs", "cfs", "cfs", "cfs",…Therefore, in order to combine these two datasets from different sources we need to do some data cleaning.
Lets first focus on cleaning the cdwr dataset to match the structure of the usgs one:
cdwr_clean <- cdwr %>%
# rename data and streamflow vars to match name of usgs vars
rename(q_cfs = value) %>%
# Add site and agency vars
mutate(Date = lubridate::ymd(measDate),
Site = ifelse(abbrev == "CLAFTCCO", "Canyon",
"Timnath"),
agency_cd = "CDWR")Now, we can join our USGS and CDWR data frames together with bind_rows().
10.2 Exploratory Data Analysis
Let’s explore the data to see if there are any trends we can find visually. We can first visualize the data as time series:
# Discharge (in CFS) through time displaying all four of our monitoring sites.
data %>%
ggplot(aes(x = Date, y = q_cfs, color = Site)) +
geom_line() +
theme_bw() +
xlab("Date") +
ylab("Discharge (cfs)") +
facet_wrap( ~ Site, ncol = 1)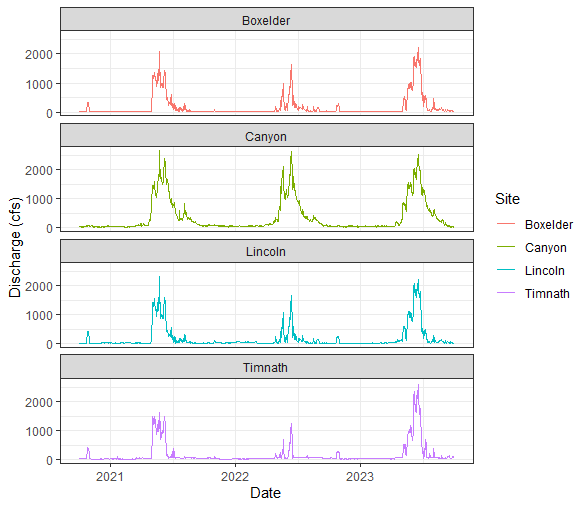
Say we wanted to examine differences in annual stream flow. We can do this with a little data wrangling, using the separate() function to split our “Date” column into Year, Month, and Day columns.
data_annual <- data %>%
separate(Date, into = c("Year", "Month", "Day"), sep = "-") %>%
# create monthly avg for plots
group_by(Site, Year, Month) %>%
summarise(monthly_q = mean(q_cfs))## `summarise()` has grouped output by 'Site', 'Year'. You can override using the `.groups` argument.# visualize annual differences across the course of each year
data_annual %>%
ggplot(aes(x = Month, y = monthly_q, group = Year)) +
geom_line(aes(colour = Year))+
facet_wrap(~Site) +
theme_bw()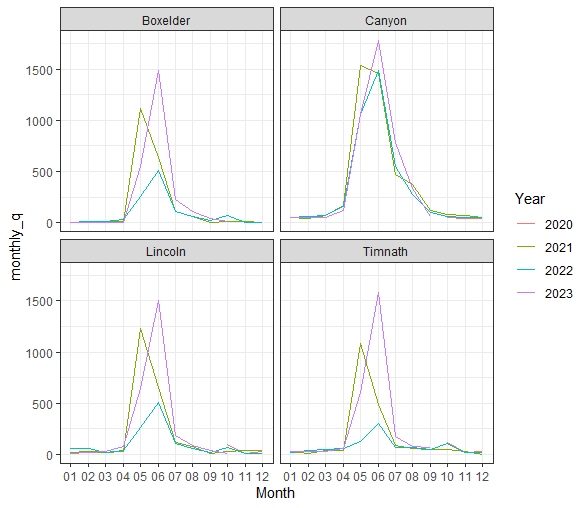
Let’s look at the daily difference in discharge between the mouth of the Cache la Poudre River (Canyon Mouth site) and each of the sites downstream. This will require some more wrangling of our data.
dif_data <- data %>%
# select vars of interest
select(Site, Date, q_cfs) %>%
# create a column of streamflow values for each site
pivot_wider(names_from = Site, values_from = q_cfs) %>%
# for each downstream site, create a new column that is the difference from the Canyon mouth site
mutate_at(c("Boxelder", "Lincoln", "Timnath"), .funs = ~ (Canyon - .)) %>%
# if you wanted to create new variables use this instead:
#mutate_at(c("Boxelder", "Lincoln", "Timnath"), .funs = list(dif = ~ (Canyon - .))) %>%
# then pivot these new columns (i.e., NOT the date and canyon columns) longer again
pivot_longer(-c(Canyon, Date))dif_data %>%
# This changes our 'name' varible to a factor, so the sites plot in order of their distance from the canyon mouth
mutate(name = fct(name, levels = c("Lincoln", "Boxelder", "Timnath"))) %>%
ggplot() +
geom_line(aes(x = Date, y = value, color = name)) +
theme_bw() +
facet_wrap("name")+
ylab("Streamflow Difference from Poudre Mouth")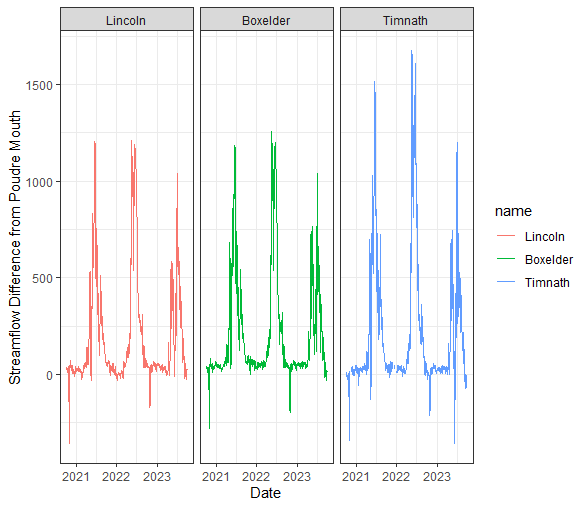
10.3 Data Analysis
Through our exploratory data analysis, it appears that stream flow decreases as we move through town. But, how can we test if these flows are significantly different, and identify the magnitude/direction of these differences?
Because we will be comparing daily stream flow across multiple sites, we can use an ANOVA test to assess this research question. We will set our alpha at 0.05.
10.3.1 Testing for normal distribution
ANOVA assumes normal distribution within each group - we can visualize each site’s data with a histogram:
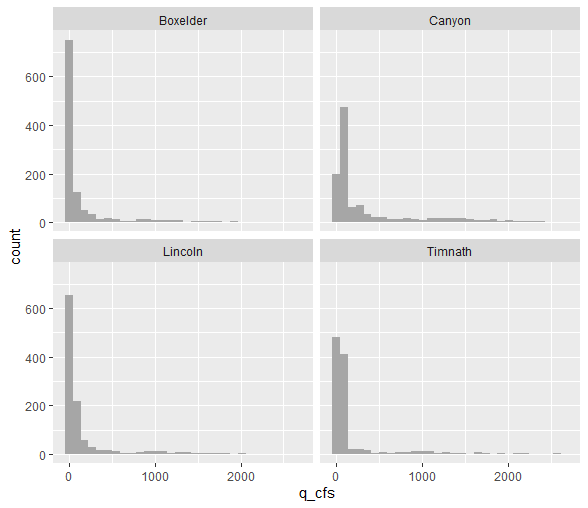
… and use the shapiro_test() function along with group_by() to statistically test for normality within each site’s daily stream flow data:
## # A tibble: 4 × 4
## Site variable statistic p
## <chr> <chr> <dbl> <dbl>
## 1 Boxelder q_cfs 0.485 1.86e-48
## 2 Canyon q_cfs 0.648 1.29e-42
## 3 Lincoln q_cfs 0.486 2.08e-48
## 4 Timnath q_cfs 0.427 2.07e-49Since the null hypothesis of the Shapiro-Wilk test is that the data is normally distributed, these results tell us all groups do not fit a normal distribution for daily stream flow. It is also quite clear from their histograms that they are not normally distributed.
10.3.2 Testing for equal variance
To test for equal variances among more than two groups, it is easiest to use a Levene’s Test like we have done in the past:
## Warning in leveneTest.default(y = y, group = group, ...): group coerced to factor.## # A tibble: 1 × 4
## df1 df2 statistic p
## <int> <int> <dbl> <dbl>
## 1 3 4334 41.8 1.31e-26Given this small p-value, we see that the variances of our groups are not equal.
10.3.3 ANOVA - Kruskal-Wallis
After checking our assumptions we need to perform a non-parametric ANOVA test, the Kruskal-Wallis test.
## # A tibble: 1 × 6
## .y. n statistic df p method
## * <chr> <int> <dbl> <int> <dbl> <chr>
## 1 q_cfs 4338 860. 3 5.36e-186 Kruskal-WallisOur results here are highly significant (at alpha = 0.05), meaning that at least one of our group’s mean stream flow is significantly different from the others.
10.3.4 ANOVA post-hoc analysis
Since we used the non-parametric Kruskal-Wallace test, we can use the associated Dunn’s test to test across our sites for significant differences in mean stream flow:
## # A tibble: 6 × 9
## .y. group1 group2 n1 n2 statistic p p.adj p.adj.signif
## * <chr> <chr> <chr> <int> <int> <dbl> <dbl> <dbl> <chr>
## 1 q_cfs Boxelder Canyon 1096 1095 28.9 1.92e-183 1.15e-182 ****
## 2 q_cfs Boxelder Lincoln 1096 1095 10.6 1.77e- 26 3.54e- 26 ****
## 3 q_cfs Boxelder Timnath 1096 1052 15.1 2.39e- 51 9.56e- 51 ****
## 4 q_cfs Canyon Lincoln 1095 1095 -18.2 2.94e- 74 1.47e- 73 ****
## 5 q_cfs Canyon Timnath 1095 1052 -13.5 1.27e- 41 3.81e- 41 ****
## 6 q_cfs Lincoln Timnath 1095 1052 4.53 5.84e- 6 5.84e- 6 ****The results of our Dunn test signify that all of our sites are significantly different from eachother mean streamflow across our sites are significantly different.
THOUGHT EXPERIMENT 1: Based on our results, which of our two gages have the greatest difference in mean daily stream flow?
THOUGHT EXPERIMENT 2: Is this an appropriate test to perform on stream flow data? Why or why not?